An interesting feature has just landed in libvips git master (and should be in the upcoming libvips 8.9): true streaming. This has been talked about on and off for five years or more, but it’s now finally happened! This post explains what this feature is and why it could be useful.
Overview
Previously, libvips let you use files and areas of memory as the source and destination of image processing pipelines.
The new VipsConnection classes let you connect image processing pipelines
efficiently to any kind of data object, for example, pipes. You can now
do this:
cat k2.jpg | \
vips invert stdin[shrink=2] .jpg[Q=90] | \
cat > x.jpg
The magic filename "stdin" opens a stream attached to file descriptor 0
(stdin), does vips_image_new_from_source(), and passes that image into
the operation. Writing to a filename with nothing before the suffix will
open a stream to stdout and write in that format.
Why is this useful
To see why this is a useful thing to be able to do, imagine how something like a thumbnailing service on S3 works.
S3 keeps data (images in this case) in buckets and lets you read and
write buckets using http GET and POST requests to addresses like
http://johnsmith.s3.amazonaws.com/photos/puppy.jpg.
Processing with a system that works in whole images, like ImageMagick, happens like this:

Reading from the left, first the data is downloaded from the bucket into a large area of memory, then the image is decompressed, then processed, perhaps in several stages, then recompressed, then finally uploaded back to cloud storage.
Each stage must complete before the next stage can start, and each stage needs at least two large areas of memory to function.
Current libvips is able to execute decode, process and encode all at the same time, in parallel, and without needing any intermediate images. It looks more like this:
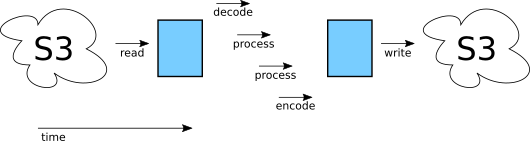
Because the middle sections are overlapped we get much better latency: the total time the whole process takes from start to finish is much lower.
However, current libvips still needs the compressed input image to be read to memory before it can start, and can’t start to upload the result to cloud storage until it has finished compressing the whole output image.
This is where true streaming comes in. libvips git master can now decode directly from a pipe and encode directly to a pipe. It looks more like this:
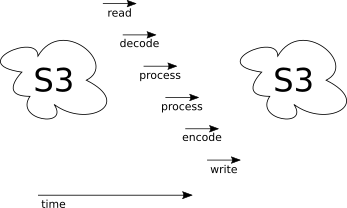
Now everything overlaps, and latency should drop again.
API
Here’s how it looks in Python:
source = pyvips.Source.new_from_descriptor(4132)
image = pyvips.Image.new_from_source(source, "")
if image.width > 1000:
# big image! .. shrink on load
image = pyvips.Image.new_from_source(source, "", shrink=2)
image = image.invert()
target = pyvips.Target.new_to_descriptor(2487)
image.write_to_target(target)
The neat part is that you can open the source twice, once to get the header and decide how to process it, and a second time with the parameters you want.
Behind the scenes, the source is buffering bytes as they arrive from the input. If you reuse the source, it’ll automatically rewind and reuse the buffered bytes until they run out. Once you switch from reading the header to processing pixels, the buffer is discarded and bytes from the source are fed directly into the decompressor.
The mechanism that supports this is set of calls loaders can use on sources to hint what kind of access pattern they are likely to need, and what part of the image (header, pixels) they are working on.
Custom sources
libvips ships with streams that can attach to files, areas of memory, and file descriptors (eg. pipes).
You can add your own connection types by subclassing VipsSource and
VipsTarget and implementing read and write methods, but this can be
awkward for languages other than C or C++.
To make custom streams easy in languages like Python, there are classes called
VipsSourceCustom and VipsTargetCustom. You can make your own stream
objects like this:
file = open(sys.argv[1], "rb")
def read_handler(size):
return file.read(size)
source = pyvips.SourceCustom()
source.on_read(read_handler)
This makes a very simple source which just reads from a file. Without a
seek handler, Source will treat this as a pipe and do automatic header
buffering.
Like any source, you can use it to make an image:
image = pyvips.Image.new_from_source(source, '')
Or perhaps:
image = pyvips.Image.thumbnail_source(source, 128)
You could make one with a seek handler like this:
file = open(sys.argv[1], "rb")
def read_handler(size):
return file.read(size)
def seek_handler(offset, whence):
file.seek(offset, whence)
return file.tell()
source = pyvips.Source()
source.on_read(read_handler)
source.on_seek(seek_handler)
A seek method is optional, but will help file formats like TIFF which seek a lot during read.
Custom output streams
Output streams are almost the same:
file = open(sys.argv[2], "wb")
def write_handler(chunk):
return file.write(chunk)
def finish_handler():
file.close()
target = pyvips.TargetCustom()
target.on_write(write_handler)
target.on_finish(finish_handler)
So you can now do this!
image = pyvips.Image.new_from_source(source, '')
image.write_to_target(target, '.png')
And it’ll copy between your two objects.
Loader and saver API
There’s quite a large chunk of new API for loaders and savers to use to hook themselves up to streams. We’ve rewritten jpg, png, webp, hdr (Radiance), tif (though only load, not save), svg and ppm/pfm/pnm to work only via this new class.
We plan to rework more loaders and savers in the next few libvips versions. The old file and buffer API will become a thin layer over the new connection system.